Tidymodels es en realidad un conjunto de paquetes de R que, al igual que Tidyverse, busca unificar la sintaxis y modo de uso al alrededor del modelado estadístico de datos. A diferencia de Tidyverse, Tidymodels no implementa nuevas maneras de, por ejemplo, aplicar el modelo lineal, si no que genera una interfaz única a partir de la cual utilizar las funciones que ya existen. De la misma manera, la salida que genera es consistente a lo largo de distintos modelos e implementaciones, y mejor aún en formato tidy.
pero hay muchos otros con objetivos específicos que completan el universo de tidymodels.
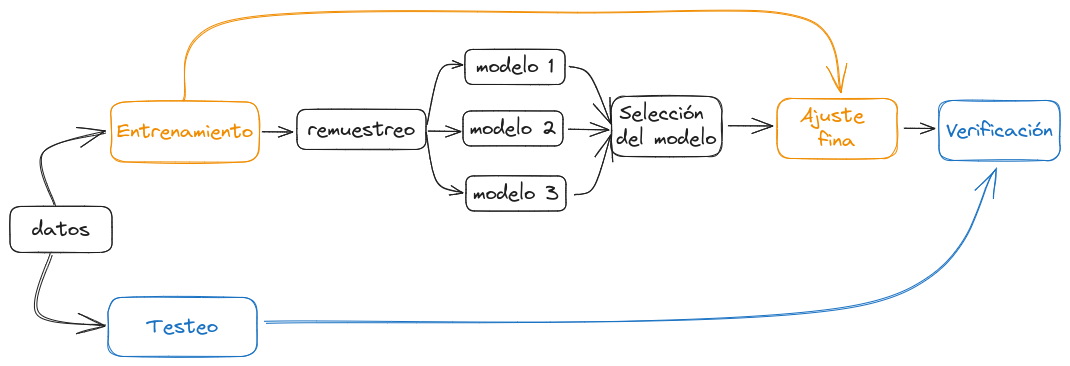
El proceso de modelado de datos
Este diagrama muestra el proceso de modelado de datos teórico. Por supuesto, en la realidad vamos y venimos entre los distintos pasos hasta ajustar cada detalle. Pero es importante tener en cuenta algunos detalles:
Cómo aprovechar los datos: es importante hacer un “presupuesto” para planificar cómo vamos a usar los datos. Si usamos el 100% de nuestra muestra en el entrenamiento de un modelo, luego no podremos hacer ningún tipo de verificación (el modelo ya conoce los datos, cualquier resultado no será válido). Por eso necesitamos dividir los datos en (al menos) entrenamiento y testeo. Usaremos rsample para esta tarea.
Qué modelo utilizar: la mayoría de las veces no sabremos cual es el mejor modelo a aplicar, dependerá en parte de nuestro objetivo: queremos hacer describir, hacer inferencias o predecir a partir de los datos? Lo interensante es probar distintos modelos para quedarnos con el mejor o utilizar una combinación. Para esto es necesario hacer un remuestreo de los datos de entrenamiento y así hacer comparaciones válidas.
La verificación: es importante hacer una verificación tanto cualitativa (visual) como cuantitativa con los el subset de testeo, pero nunca con los datos de entrenamiento!
Datos de cultivos
Vamos a trabajar con datos de rendimiento de cultivos que incluyen información sobre la floración, la altura del cultivo, la campaña, el tipo de ensayo, la distacia entre surcos entre otras cosas. Con esta información intentaremos generar un modelo que nos permita predecir la variable aceite_porcentaje.
Rows: 6856 Columns: 13
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): campania, tipo_ensayo, epoca, tipo_siembra, testigo, visible, cultivar
dbl (6): floracion_dias, altura_cm, densidad_sem, rendimiento, aceite_porcen...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
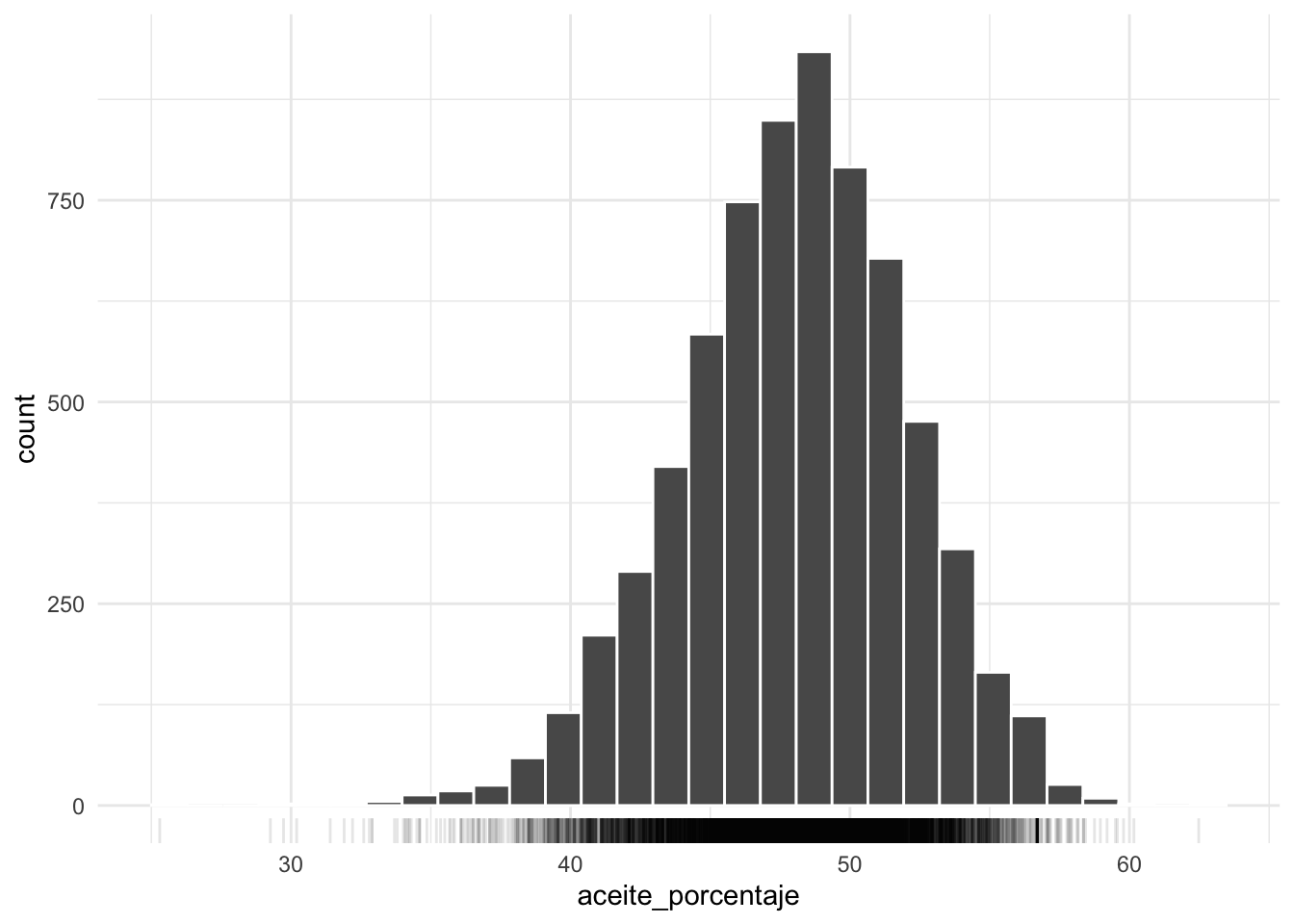
La variable aceite_porcentaje tiene la siguiente distribucuón:
Esta base de datos tiene en total 6856 registros de distintos ensayos de cultivos. Vamos a dividir los datos en 2 subsets de entrenamiento (cultivos_train) y testeo (cultivos_test). En primer lugar la función initial_split() divide los datos en 2 utilizando el argumento prop para definir cuantos datos iran a cada subset. En ese caso usamos por defecto 3/4, es decir, el 75% de los datos iran al entrenamiento y el 25% quedará para el testeo. Decidir este porcentaje es un problea en si mismo!
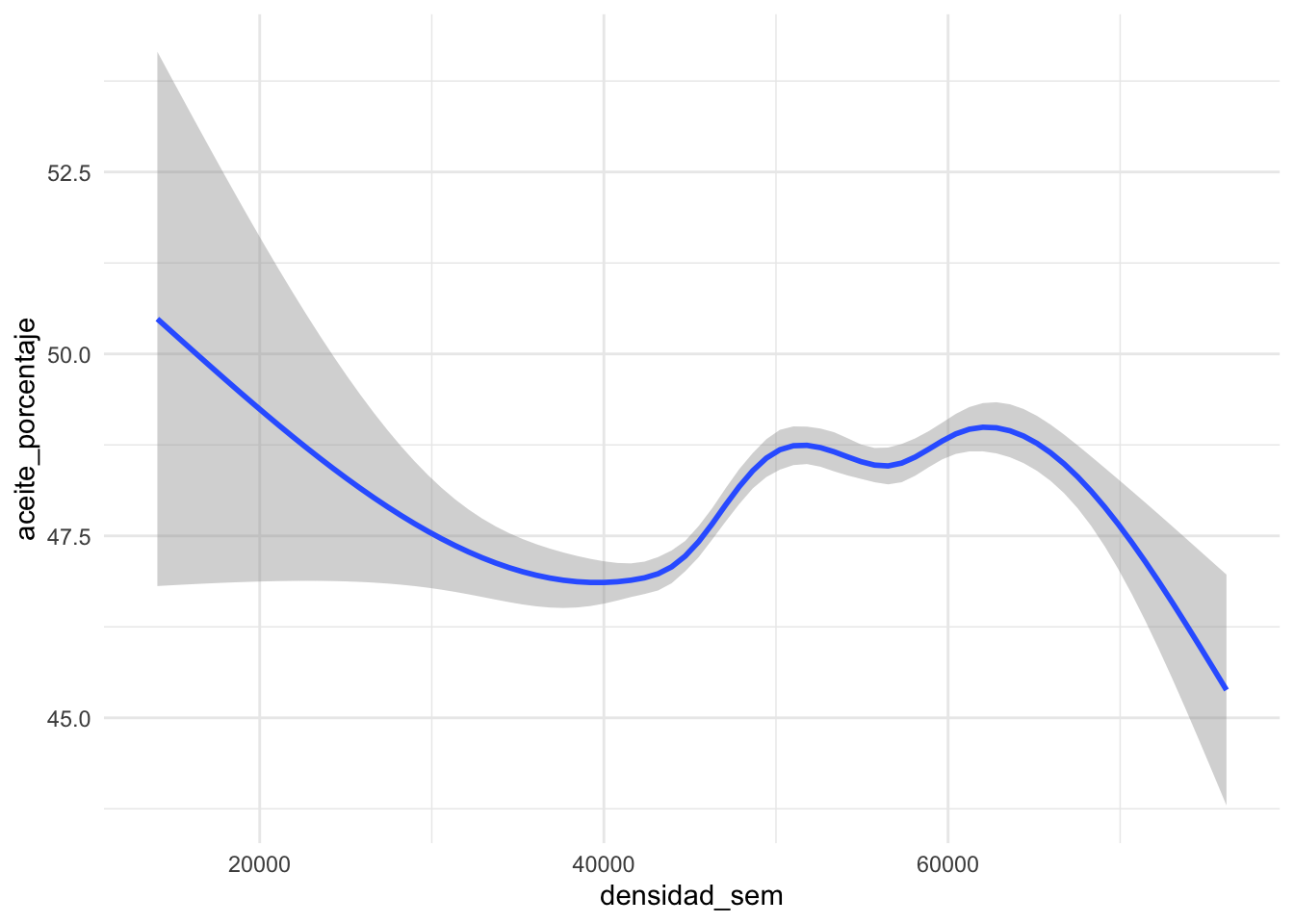
Veamos ahora que pinta tiene nuestra variable de interes en relación con otras, por ejemplo densidad_sem. Inicialmente no parece haber una relación muy clara.
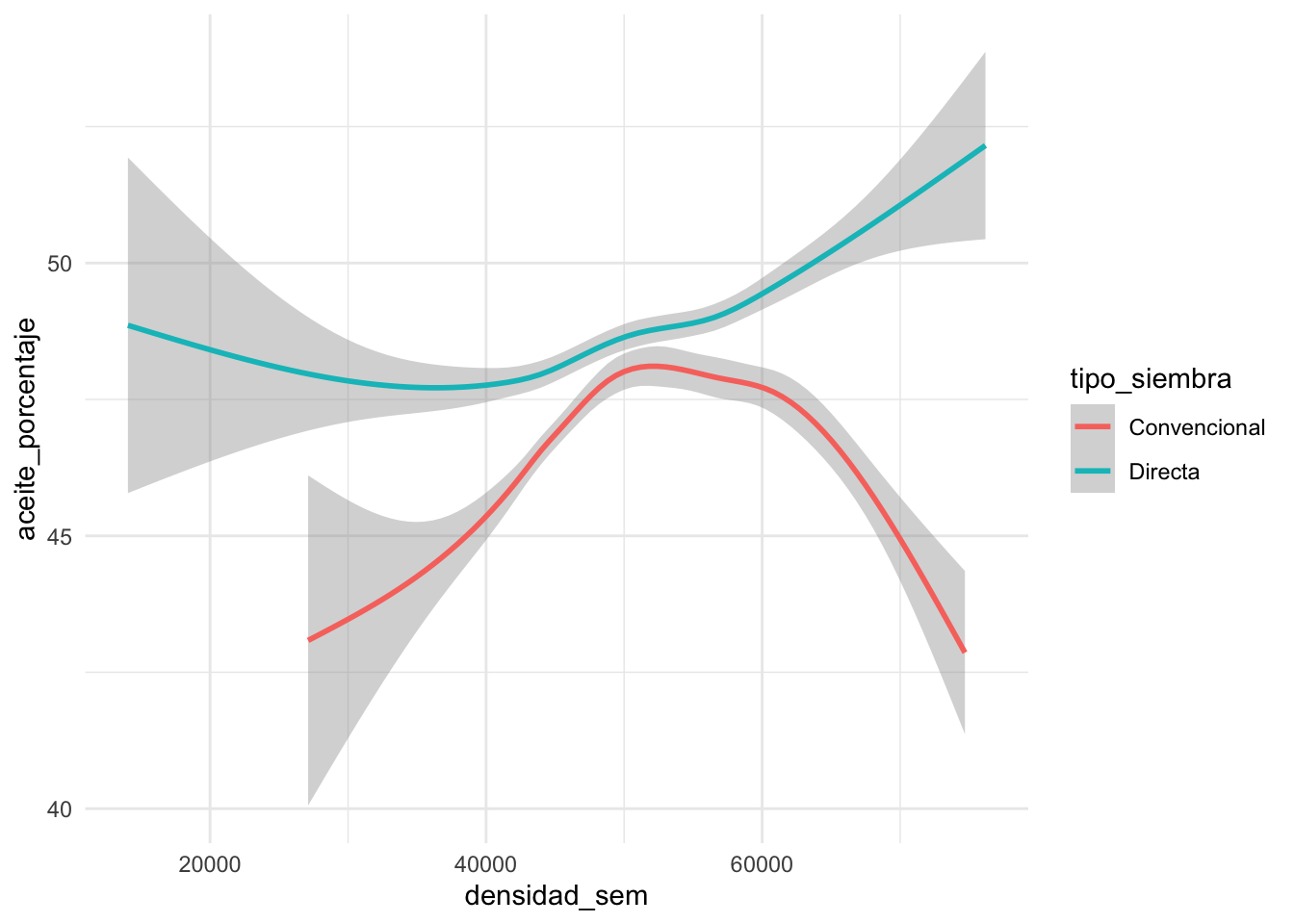
Sin embargo si incluimos tipo_siempra como tercera variable, vemos que esta nueva variable podría llegar a explicar, en parte el comportamiento de aceite_porcentaje.
Comencemos ahora con el preprocesamiento de los datos. Para esto crearemos una receta, es decir una serie de pasos que realicen las transformaciones necesaria para dejar los datos listos para el modelado. A diferencia de otras implementaciones con tidymodel separamos completamente el preprocesamiento del modelado. De esta manera modularizamos el proceso y podemos utilizar la misma receta para aplicar modelos distintos.
Crearemos la receta con los datos de entrenamiento pero luego podremos aplicar estos pasos también a los datos de testeo. Iniciamos la receta con la función recipe() indicando la formula, en este caso queremos evaluar la relación de aceite_porcentaje en función de todas las otras variables.
receta_aceite <-recipe(aceite_porcentaje ~ ., data = cultivos_train)
El siguiente paso es trabajar con predictores categóricos, para esto sumamos un paso a la receta step_dummy() que convierte las variables nominales (caracteres o factores) en variables numéricas binarias. En este caso aplicamos el paso a todos os predictores nominales. Aquí vemos además que la receta es compatible con el uso de la %>% por lo que podemos ir sumando los paso uno detrás del otro.
receta_aceite <-recipe(aceite_porcentaje ~ ., data = cultivos_train) %>%step_dummy(all_nominal_predictors())
• Centering and scaling for: all_numeric_predictors()
Esta receta además, define claramente las transformaciones que hacemos en los datos por lo que es reproducible.
Podríamos encadenar la función prep() para preparar los datos usando la receta pero en nuestro caso ejecutaremos todos los pasos necesarios en un workflow.
Definiendo el modelo
El siguiente paso es definir el modelo a aplicar. Nuevamente usamos tidymodels que tienen funciones que funcionan como interfaz con implementaciones en distintos paquetes. Podés revisar la lista de modelos disponibles acá. En nuestro caso vamos a arrancar con el modelo linea usando la función linear_reg().
modelo_lineal <-linear_reg()
Por defecto esta función usa lm del paquete stats de R base pedro podríamos usar muchos otros engines, es decir, otras implementaciones al modelo lineal como glm y glment. Para setear un engine usamos set_engine():
modelo_lineal <-linear_reg() %>%set_engine("lm")
En algunos casos necesitaremos tener paquetes específicos instalados, por ejemplo lme requiere un extension del paquete parsnip.
modelo_lineal
Linear Regression Model Specification (regression)
Computational engine: lm
Ya tenemos el segundo paso, el modelo. Pero como habrás notado, en ningún momento modelo_lineal se cruzó con nuestros datos. Vamos a unir todo en un workflow.
Uninendo todo
Un workflow es un obejto que incorpora toda la información necesaria para ajustar y hacer predicciones en base a un modelo. Iniciamos nuestro workflow con la función workflow():
wflow_lm <-workflow()
Y luego con las funciones add_model() y add_recipe() agregamos el modelo y la receta que creamos recién.
Con el workflow completo ahora si podemos ajustar el modelo usando los datos de entrenamiento:
modelo_fit <-fit(wflow_lm, data = cultivos_train)
Warning: Categorical variables used in `step_interact()` should probably be avoided;
This can lead to differences in dummy variable values that are produced by
?step_dummy (`?recipes::step_dummy()`). Please convert all involved variables
to dummy variables first.
El objeto modelo_fit contiene muchísima información incluyendo el modelo, la receta y entre otras cosas nos permitirá extraer predicciones. Esto lo hacemos con la función predict
# A tibble: 6 × 1
.pred
<dbl>
1 43.5
2 44.1
3 47.2
4 44.7
5 NA
6 50.9
Además de predecir el valor medio, también podemos estimar intervalos de confianza con la misma función:
mean_predict <-predict(modelo_fit, cultivos_test)conf_int_pred <-predict(modelo_fit, new_data = cultivos_test, type ="conf_int")
Esto genera un par de tibbles con columnas .pred_lower y .pred_upper que son los límites inferiores y superiores de ese intervalo de confianza.
Verificación
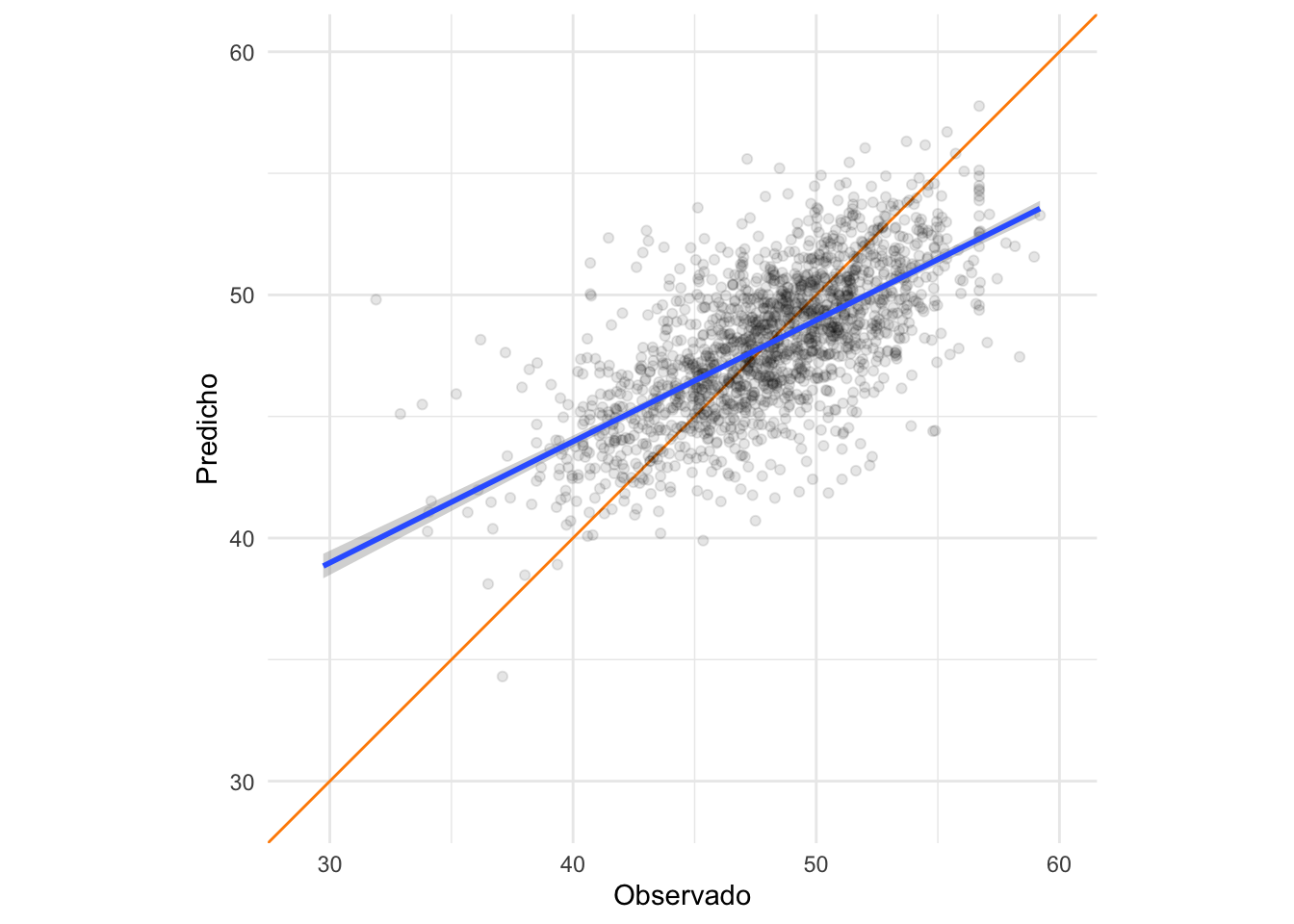
Veamos como le fue a nuestro modelo (spoiler alert: bastante mal). Primero vamos a graficar los valores predichos de aceite_porcentaje en función de los observados y que tenemos en nuestro subset de testeo.
Si nuestro modelo fuera “perfecto” todos los puntos deberían caer alrededor de la linea naranja. Sin embargo tenemos puntos que se alejan bastante. Desde este punto de vista más cualitativo vemos que el modelo no es muy bueno. Calculemos ahora cual seria el error que cometeríamos si usamos el modelo para predecir un valor de aceite_porcentaje en el futuro.
rmse(aceite_predic, aceite_porcentaje, .pred)
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 3.08
En este caso calculamos la raiz del error cuadrático medio o rmse con la función rmse() del paquee yardsick. El resultado es 3.0757701, esto significa que al estimar aceite_porcentaje con el modelo cometemos en promedio un error de 3.0757701.
Extra!
Una herramienta muy poderosa que implementa Tidymodels es el remuestreo. Esto es generar subsets de datos tomando datos de manera aleatoria a partir de un data set original. En este caso podemos aplicar el remuestreo para hacer un cálculo más robusto del error, generando muestras y calculando el error para cada una de ellas.
# A tibble: 10 × 4
resample .metric .estimator .estimate
<chr> <chr> <chr> <dbl>
1 1 rmse standard 3.10
2 10 rmse standard 2.99
3 2 rmse standard 2.99
4 3 rmse standard 3.07
5 4 rmse standard 3.27
6 5 rmse standard 3.09
7 6 rmse standard 3.03
8 7 rmse standard 3.05
9 8 rmse standard 3.07
10 9 rmse standard 2.99
Tenemos ahora 10 estimaciones del error calculadas a partir de cada submuestra. Podemos calcular el promedio de esa estimación y compararla con el error que obtuvimos usando el subset de testeo completo.